Парсинг сайтов (с преодолением защиты)
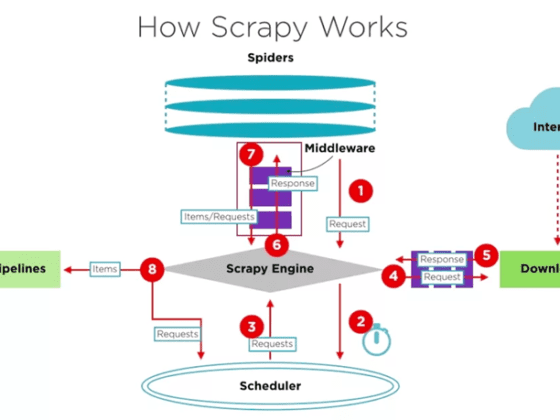
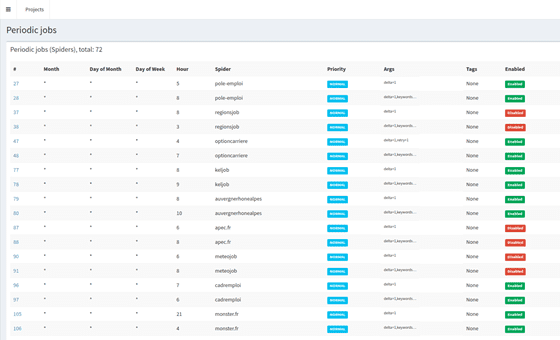
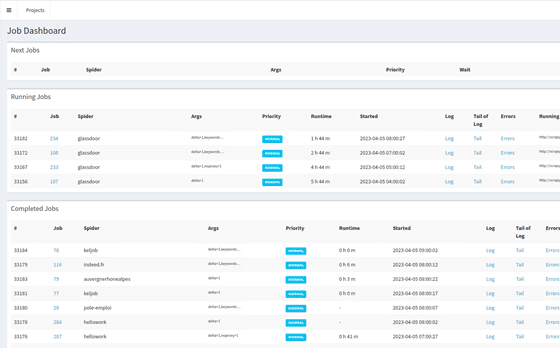
Парсинг сайтов:
Парсинг (веб-скрапинг) сайтов – это процесс автоматического сбора данных с веб-страниц. Он может использоваться для извлечения информации о товарах, вакансиях, резюме, котировках и других данных. В зависимости от целей и типов данных, существует несколько подходов к парсингу.
Типы данных для парсинга:
Товары и цены: Этот тип парсинга может использоваться, например, для сравнения цен на различных интернет-магазинах. Важно отметить, что некоторые веб-сайты предоставляют специальные API для доступа к своим товарам и ценам, что может быть более надежным способом получения данных.
Вакансии и резюме: Парсинг вакансий и резюме может помочь работодателям или соискателям находить подходящие вакансии или кандидатов. Однако это также может нарушать политику некоторых веб-сайтов.
Котировки: Парсинг котировок из финансовых и биржевых сайтов может использоваться трейдерами и инвесторами для анализа рынка. Здесь также следует обратить внимание на наличие официальных API для доступа к финансовой информации.
Преодоление защиты:
Преодоление защиты, такой как CAPTCHA или ограничения скорости запросов, является сложной задачей. В некоторых случаях, защита может быть нарушена с использованием инструментов для автоматизации браузера, таких как Selenium, которые могут эмулировать человеческое взаимодействие с сайтом.
Однако стоит учитывать, что преодоление защиты может быть незаконным или нарушать политику сайта. Многие веб-сайты запрещают парсинг и устанавливают ограничения для автоматических запросов, чтобы предотвратить перегрузку сервера.
Этика и юридические аспекты:
При использовании парсинга важно соблюдать этические и юридические нормы. Некоторые веб-сайты запрещают парсинг в своих условиях использования, и нарушение этих условий может привести к правовым последствиям.
В целом, парсинг веб-сайтов с преодолением защиты является сложным и контекстно зависимым процессом. Прежде чем приступать к парсингу, необходимо провести исследование и оценку юридических и этических аспектов, а также рассмотреть доступные альтернативы, такие как использование официальных API, если они предоставляются.
Задача
Цель проекта по парсингу сайтов с преодолением защиты – создать систему для автоматического сбора различных данных, таких как товары, вакансии, резюме и котировки, с веб-сайтов, которые могут иметь защитные механизмы. Проект стремится предоставить возможность собирать ценную информацию с разных ресурсов без ручного вмешательства.
Этапы разработки
1.Планирование и Анализ: Определение типов данных для сбора, выбор целевых веб-сайтов и методов их защиты.
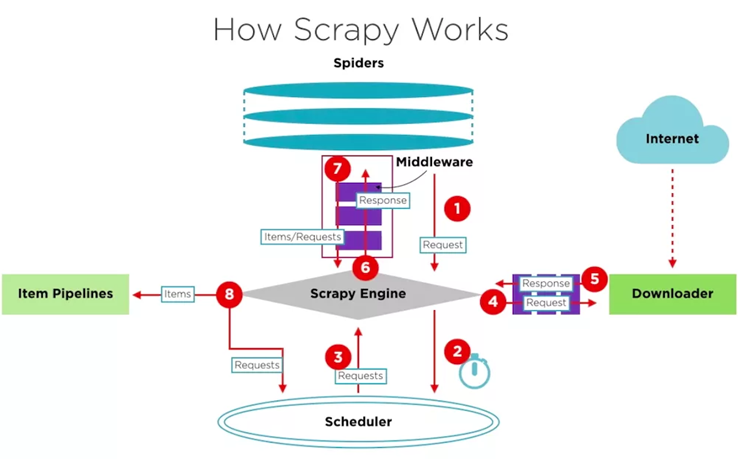
2.Выбор Технологий: Определение оптимального стека технологий для парсинга, включая Selenium, Splash, Scrapy, SpiderKeeper и Scrapyd.
3.Разработка Парсеров: Создание парсеров для разных типов данных (товары, вакансии, резюме, котировки) с учетом защиты.
4.Преодоление Защиты: Разработка механизмов для обхода и преодоления защитных механизмов сайтов, таких как CAPTCHA и IP-баны.
5.Интеграция с Splash и Selenium: Интеграция Splash и Selenium для обработки динамических и сложных веб-страниц.
6.Управление Парсерами: Внедрение SpiderKeeper для удобного управления парсерами и мониторинга их состояния.
7.Создание Scrapyd Сервера: Разработка Scrapyd сервера для запуска парсеров на удаленных машинах.
8.Тестирование и Отладка: Проведение тестирования парсеров, обработки данных и защитных механизмов.
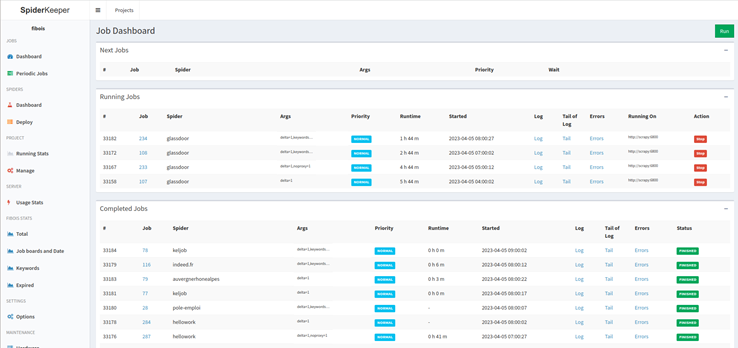
Технологии и инструменты для разработки проекта
Техническая Часть:
1.Стек Технологий: Использование Selenium для автоматизации веб-браузера, Splash для обработки JavaScript, Scrapy для веб-парсинга, SpiderKeeper для управления и мониторинга и Scrapyd для удаленного выполнения.
2.Анти-защита: Разработка алгоритмов и методов для преодоления CAPTCHA, обхода IP-банов и других защитных механизмов.
3.Автоматизация: Создание механизмов для автоматического запуска и контроля парсеров.
Функциональность:
1.Сбор Разных Типов Данных: Возможность сбора информации о товарах, вакансиях, резюме, котировках и других данных.
2.Преодоление Защиты: Разработка алгоритмов для преодоления CAPTCHA, IP-банов и других защитных механизмов.
3.Удобное Управление: Использование SpiderKeeper для управления и мониторинга парсеров.
4.Масштабирование: Использование Scrapyd для удаленного выполнения парсеров на нескольких машинах.
Заключение и результаты разработки
Автоматизация Сбора Данных: Создание системы, способной автоматически собирать ценные данные с различных веб-ресурсов.
Эффективное Преодоление Защиты: Разработка механизмов, позволяющих успешно обойти защитные механизмы сайтов.
Больше Доступной Информации: Получение доступа к данным, которые были бы сложно или невозможно собрать вручную.
Дополнительные Возможности:
Анализ и Обработка Данных: Внедрение механизмов для анализа и обработки собранных данных.
Интеграция с Базами Данных: Создание механизмов для сохранения и управления собранными данными.
Заключение: Система парсинга сайтов с преодолением защиты – это проект, направленный на автоматический сбор ценных данных с веб-ресурсов с использованием различных технологий, таких как Selenium, Splash, Scrapy, SpiderKeeper и Scrapyd. Проект стремится обеспечить эффективный сбор информации при преодолении защитных механизмов, обеспечивая более доступный и широкий доступ к данным.